Cluster Information
Details on how to request resources to run your jobs are available here.
The current usage policy (that can be seen running qconf -ssconf) implements a balanced approach to job scheduling, with significant consideration given to CPU usage and job priorities. Briefly, jobs are executed in a first-come first-serve basis, once you submit a job, given that the requested resources are available, your job will be executed by the scheduler. If submitting several jobs you can adjust their priorities (with qalter), and this will be taken into account by the scheduler.
Queue Information
Last update: Sun Jun 28 08:40:47 2026
- all.q@elysium.bioinfo.cluster: Slots Total: 80, Slots Used: 0, Load Avg: 8.00000
- all.q@figsrv.bioinfo.cluster: Slots Total: 56, Slots Used: 0, Load Avg: 0.00000
- all.q@neotera.bioinfo.cluster: Slots Total: 48, Slots Used: 0, Load Avg: 0.00000
- all.q@telura.bioinfo.cluster: Slots Total: 80, Slots Used: 0, Load Avg: 0.00000
- introns.q@elysium.bioinfo.cluster: Slots Total: 120, Slots Used: 0, Load Avg: 8.00000
Running Jobs Information
| Queue | Job Number | Job Name | Job Owner | State | Slots | Start Time |
|---|
Pending Jobs Information
| Job Number | Job Name | Job Owner | State | Slots | Submission Time |
|---|
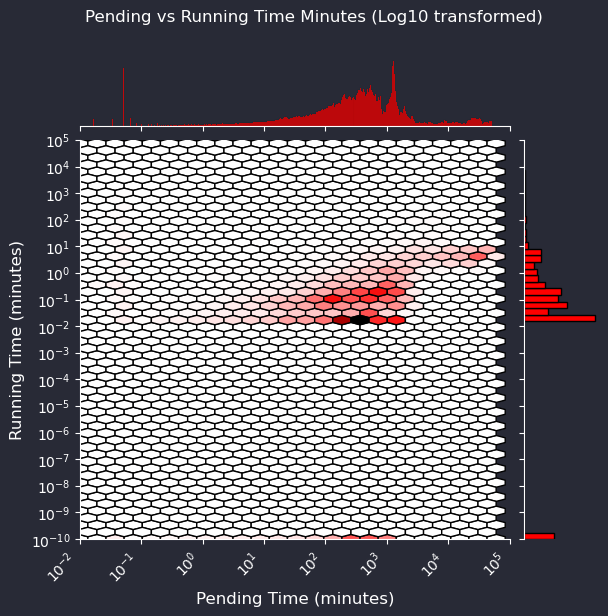
Waiting and running times
The figure below shows the distribution of waiting/pending and running times in minutes. Waiting or pending time is the interval between submitting a job to the queueing system and when it actually starts running on the computing node. In our cluster, most jobs, in average, wait less than 35.07 minutes (approximately 0.585 hours) to start running. Once the jobs start running, most of them, in average, finish within 141.29 minutes, based on 16227 jobs.